Extracting Companies House data and storing it in BigQuery
This tutorial uses Optimus Mine to download the Companies House data product and store it in Google BigQuery. Companies House is the UK business register which holds the details on over 4.5 million companies.
The goal of this tutorial is to introduce you to the database export features in Optimus Mine.
Before you begin
If you do not have Optimus Mine installed already, follow the installation guide to download & install Optimus Mine on your machine.
You will require a Google Cloud account to use BigQuery. If you do not have one visit https://cloud.google.com/ to get a account with $300 credit for free.
Step one: Create a BigQuery dataset
- Visit https://console.cloud.google.com/bigquery. If you have not used BigQuery before you will need to enable it first and the visit the URL again.
- Click onto your project on the left hand side menu.
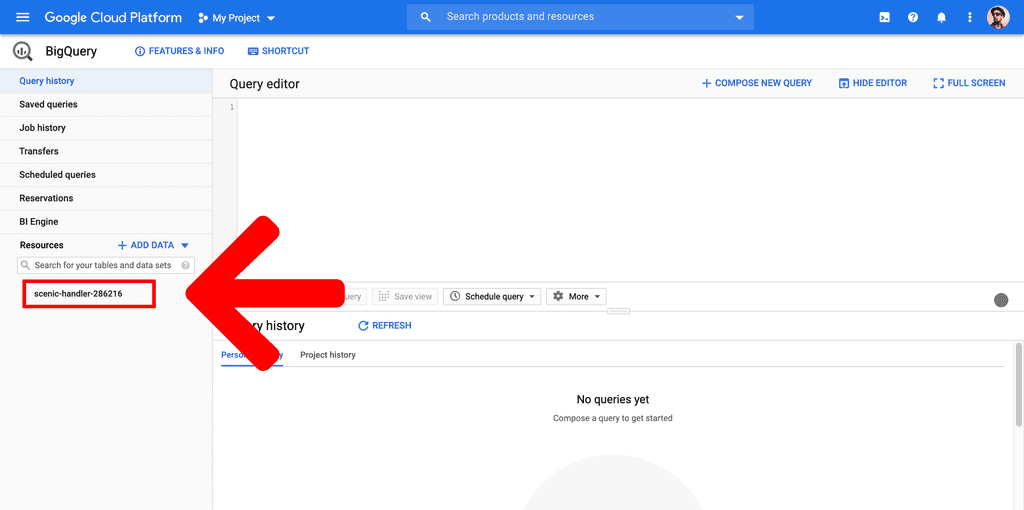
- Click the
CREATE DATASETbutton on the right hand side.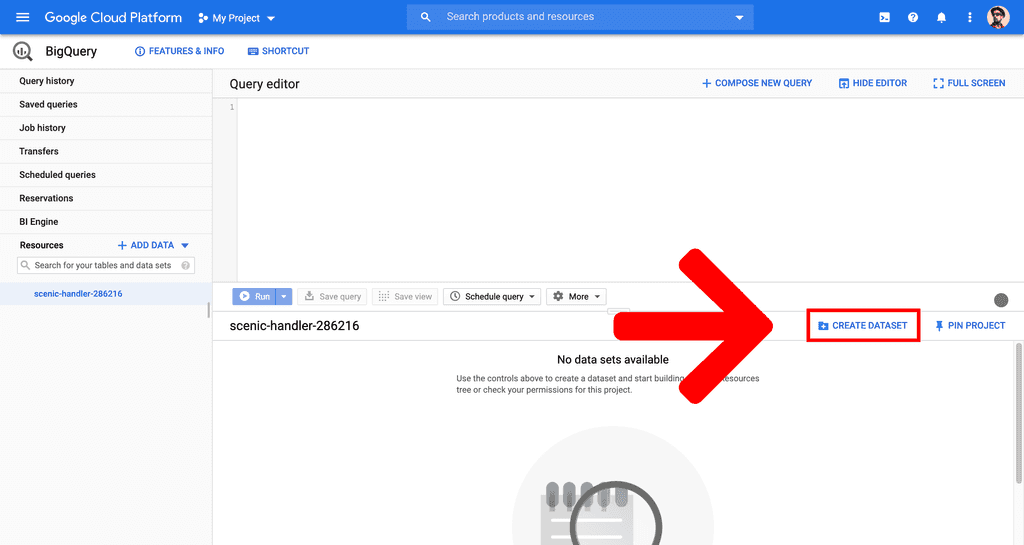
- Enter a name for your dataset under
Dataset IDand optionally choose a data location, then hit theCreate datasetbutton at the bottom.
Step two: Create a service account
- Visit https://console.cloud.google.com/iam-admin/serviceaccounts.
- Click the
CREATE SERVICE ACCOUNTbutton at the top of the page.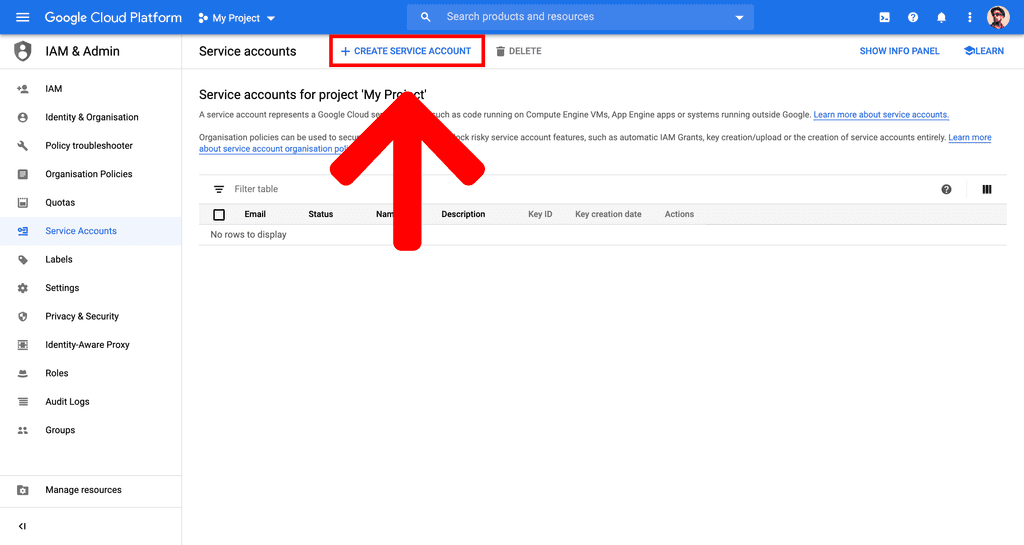
- Enter a service account name and hit the
CREATEbutton. It’s a good idea to enter something that will help you identify what this service account is being used for later down the line. - Click on the
Select a roledropdown and select theBigQuery>BigQuery Adminrole, then click onCONTINUE. - You don’t need to do anything on the next screen so simply click the
DONEbutton. - Click on your newly created service account.
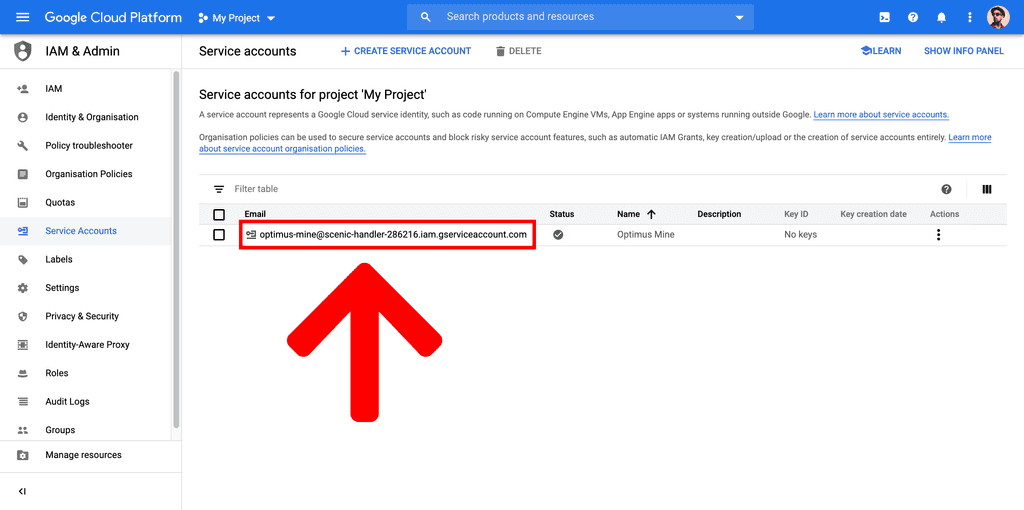
- Scroll to the bottom of the page and click
ADD KEY>Create new key. - Click on
CREATEon the popup window and save the key on your computer. You’ll need this in a moment so make sure you take note of where you’re saving it.
Step three: Create a new project
- Launch the Optimus Mine application.
- On the top right hand side, click New Project.

- Enter a name for your new project in the Title field.

Step four: Configure your pipeline
Next you create the pipeline configuration. The following YAML document is used to create the
pipeline you will use to scrape the RSS feed and create the JSON file. Copy & paste it into the
editor below the title field, replacing MY_DATASET with the one you chose in step one and
MY_SERVICE_ACCOUNT_KEY with the name of the service account file you downloaded in step 2, then
hit Save.
defaults:
threads: 1
timeout: 5m
verbose: true
tasks:
- name: zip_url
task: scrape
engine: xpath
input: https://download.companieshouse.gov.uk/en_output.html
schema:
type: string
source: //ul[1]/li/a/@href
filter:
- type: prepend
string: https://download.companieshouse.gov.uk/
- name: company_data
task: scrape
engine: csv
schema:
type: object
properties:
name:
source: CompanyName
type: string
company_number:
source: CompanyNumber
type: string
address_line_1:
source: RegAddress.AddressLine1
type: string
address_line_2:
source: RegAddress.AddressLine2
type: string
town:
source: RegAddress.PostTown
type: string
county:
source: RegAddress.County
type: string
country:
source: RegAddress.Country
type: string
postcode:
source: RegAddress.PostCode
type: string
type:
source: CompanyCategory
type: string
status:
source: CompanyStatus
type: string
sic_1:
source: SICCode.SicText_1
type: string
sic_2:
source: SICCode.SicText_2
type: string
sic_3:
source: SICCode.SicText_3
type: string
sic_4:
source: SICCode.SicText_4
type: string
- name: db_export
task: export
engine: bigquery
project: myproject
dataset: MY_DATASET
table: companieshouse
credentials: '{{ userDir }}/Desktop/MY_SERVICE_ACCOUNT_KEY.json'
replace: trueConfiguration details
Let’s walk through each of the properties in your configuration to understand what they do.
defaults:
In this scraper we have three tasks, 2 scrapes and an export. Defaults apply to all tasks in your project.
threads: 1
The threads determines how many HTTP requests you would like to make concurrently. Here we’re just downloading a single ZIP file and then parsing one large CSV so one thread will suffice.
timeout: 5m If a HTTP request has not completed within 5 minutes the scraper will consider it
failed.
verbose: true
Enables detailed logging which can help you identify problems if your scraper is not working as
intended. You would usually set this to false once your scraper is working.
tasks:
Contains the array of all your pipeline tasks.
The zip_url task
name: zip_url
This sets the name of the task to “zip_url”. The name will be displayed in the log messages relating to this task.
task: scrape
This tells Optimus Mine that this task as a scraper, meaning that input values will be treated as
URLs and requested via HTTP.
engine: xpath
Tells the scraper to parse the data as HTML using XPath to extract values. We use xpath to begin with because we are scraping the download links from a HTML webpage.
input: https://download.companieshouse.gov.uk/en_output.html
The input passes data to your task. In this example it tells the scraper to scrape the URL
https://download.companieshouse.gov.uk/en_output.html.
schema:
The schema contains the information on how to parse & structure the scraped data.
type: string
This tells the parser to treat the scraped data as a string of text.
filter:
Filters are used to manipulate data in your pipeline. Here we’ve set type: prepend to add the
string https://download.companieshouse.gov.uk/ to the beginning of our scraped value. This is
because the URL on the page is relative and we need to make it an absolute URL for the next task to
scrape it.
The company_data task
name: company_data
This sets the name of the task to “company_data”. The name will be displayed in the log messages relating to this task.
task: scrape
This tells Optimus Mine that this task as a scraper, meaning that input values will be treated as
URLs and requested via HTTP.
engine: csv
Tells the scraper to parse the data as CSV, using the column names from the very first row in
source to extract the data.
schema:
The schema contains the information on how to parse & structure the scraped data.
type: object
Setting type to object tells the parser that each item is a key-value map. Usually you’d set the
type to array for any page or file that you want to extract multiple items from, however for
CSVs this is optional as it will get each row anyway.
properties:
Contains the schema for each key-value pair in the object. The keys nested directly under
properties (i.e. name, company_number etc.) define the keys in the outputted data.
source: CompanyName, source: CompanyNumber etc.
Since engine is set to csv, the source parameter contains the name of the column (as defined
in the header row) that you’d like to extract.
type: string
This tells the parser to treat the scraped data as a string of text.
The export task
name: db_export
This sets the name of the task to “db_export”. The name will be displayed in the log messages relating to this task.
task: export
This tells Optimus Mine that this task as an export, meaning that incoming values from previous tasks will be exported.
engine: bigquery
The bigquery engine is used for storing the exported data in Google BigQuery.
project: myproject
The name of the Google Cloud project. Replace this with the name of the project you created earlier.
dataset: MY_DATASET
The name of the BigQuery dataset. Make sure you replace this with the name of the dataset you created in step one.
table: companieshouse
The name of the BigQuery table that will be created. Feel free to change this if you like.
credentials: '{{ userDir }}/Desktop/MY_SERVICE_ACCOUNT_KEY.json'
The path to a local service account file. Replace this with the name of the service account file you downloaded in step two.
Note:
{{ userDir }}always points to the current user directory e.g.C:\Users\YOUR_USERNAMEon windows,/Users/YOUR_USERNAMEon Mac and/home/YOUR_USERNAMEon Linux.
replace: true
Delete existing data in target table. This ensures that if you run it multiple times you won’t end up with duplicate data in your table.
Step five: Run the pipeline
You’re all set. Simply click on Start Job to run the pipeline.

Once completed you should see the company data in Google BigQuery.
Whats next
- To learn more about the schema used for parsing data, see the Parsing Data page.
- To learn more about the filters used for manipulating data, see the Filters page.
- To dive into detail about all the other configuration properties, see the Configuration Reference.